我们知道,在kubernetes中,有5个主要的组件,分别是管理节点上的kube-apiserver、kube-controller-manager和kube-scheduler,node节点上的kubelet和kube-proxy。这其中kube-apiserver是对外和对内提供资源的声明式API的组件,其它4个组件都需要和它交互,在这个交互过程中,有一个非常关键的机制就是list-watch。我们知道kube-apiserver提供了一个kubernetes中各种资源的增删改查的接口,不对需要对内给这4个组件用,还需要给外外部的用户以及集群内可能安装的插件使用,因此它接收到的请求量是十分巨大的,为了减少这种请求量,降低kube-apiserver的压力,便设计出了list-watch机制。client端在跟server端长期进行交互时,并不是每次需要查询时都去调用server的接口,而是使用list+watch的方式来维护一个缓存将server端的数据缓存起来,当需要获取数据的时候直接从缓存中获取,一方面可以降低server端的压力,另一方面也可以减少自己获取数据的时间。当然,增删改还是需要调用server端的接口。
本文的目的是将list-watch的机制搞清楚,各位看官且往下看。
说明:本文使用的k8s代码为1.13版本,其他版本代码可能会有少许差异。
0、啥是list-watch
在k8s中,list-watch本质上还是client端监听k8s资源变化并作出相应处理的生产者消费者框架。因此在分析这部分的代码之前就会有问题在脑海中:生产者是谁?消费者是谁?传递了啥?怎么传递的?
除此之外,往往生产者只有一个,消费者有多个,这种情况下怎么保证每个消费者都能收到消息?
好,带着这些问题,我们慢慢往下看。
0.1、list与watch
从字面上看,list就是获取静态的所有数据,而watch则是只关心发生了变化的那部分。对于client端而言,list是获取当前所有值列表的方法,主要用来查询,而watch则是用来监听每个资源的增删改事件。list是一般的rest api中都会实现的功能,我们这里重点讲一下watch。
0.2、使用场景
在阅读list-watch的代码之前,我们来先思考一下它的使用场景。根据文章开头说到的一些功能,我们可以梳理部分需求:
- 可以
watch特定的资源,并根据资源的变动类型(增删改)进行不同的处理 watch到变化时将这个变化加如到队列中,由处理逻辑从队列中取,将事件的生产和消费分离开来- 想要查询某个资源时只需要从缓存中获取,不需要向
kube-apiserver发请求 - 对于某些特定的资源,除了能
watch变化以外,还能定期产生变化的事件,用来做周期性检查 - 多个不同的
controller可能需要watch同一个资源,因此希望能在同一个watch的架构中能共享缓存并且能分别接收同一个资源的相同事件
0.3、代码目录
基本数据结构和算法的代码主要位于staging/src/k8s.io/client-go/tools/cache这个目录中,其中去掉UT测试的文件之后约3.6k代码,十分精巧:
1 | . |
0.4、list-watch的架构
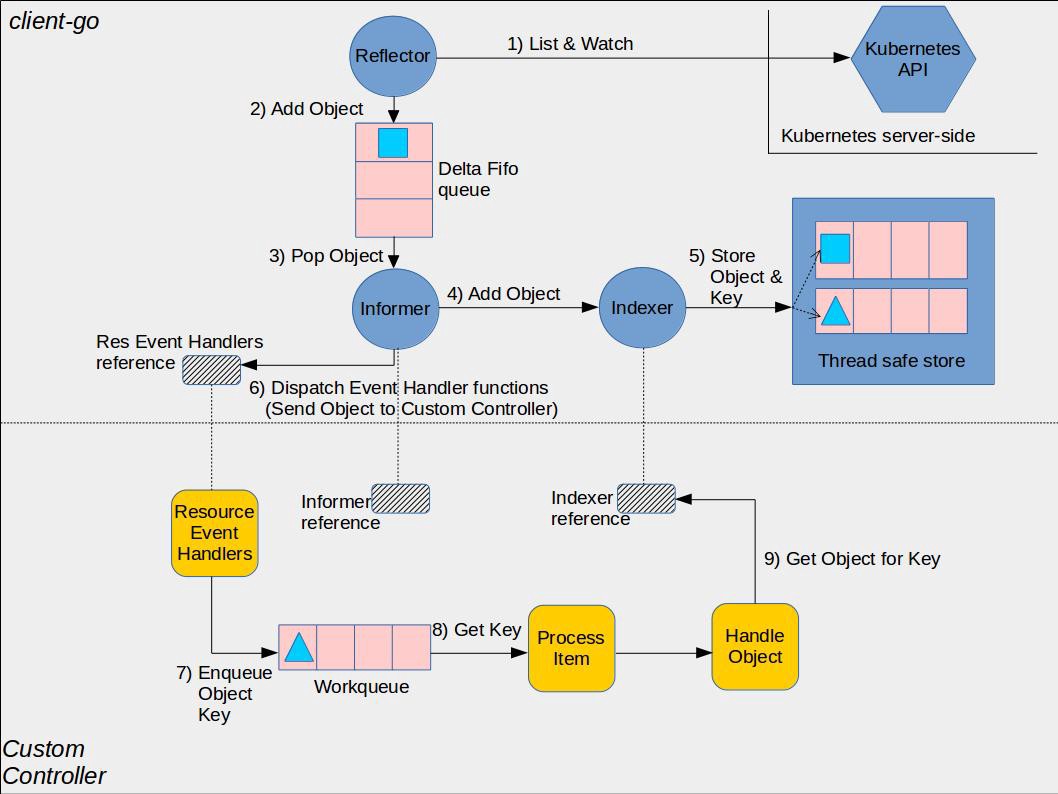
1、数据结构
1.1、基础数据结构threadSafeMap和cache
1.1.1、threadSafeMap
前面说到list-watch本质上是一个生产者消费者框架,最关键的是数据的传递,那么传递的数据的数据结构很重要,在list-watch中,最为底层的数据结构其实是一个线程安全的map:
代码位于staging/src/k8s.io/client-go/tools/cache/thread_safe_store.go
1 | // threadSafeMap implements ThreadSafeStore |
可以看到这里的threadSafeMap的结构非常简单:
lock sync.RWMutex是一个读写锁,用来保证线程安全items map[string]interface{},这是一个key为string、value是任意类型的map,也是实际数据存放的最关键的数据结构,所有的操作最终都是跟这个map打交道,key是存储对象的唯一索引,value是存储的对象indexers Indexers是用于给map中的value数据做检索(也就是计算value的key)的函数,Indexers实际的数据结构是map[string]IndexFunc,注意可以有多个索引函数,且每个函数的返回值可以是多个。可以把IndexFunc理解为聚类函数。常用的IndexFunc有MetaNamespaceIndexFunc(返回对象的namespace)和indexByPodNodeName(返回Pod对象所在节点的名字)。indices Indices则是保存索引后的数据的map[][]sets.String,第一个key是Indexers中索引函数的名字,第二个key是这个索引函数返回值的索引,sets.String则是对应该索引值的所有items对象的key,这是一个已经按照索引分类好了的三维map。
注:关于
threadSafeMap中的indexers和indices这两个元素的作用,后面会在Indexer中继续说明,这其实是list-watch之所以高效的一个重要原因。
1.1.1.1、实现的接口ThreadSafeStore
不难看到threadSafeMap是一个私有的结构体,实际在使用时是通过它所实现的接口ThreadSafeStore来对里面的map进行数据操作:
1 | // ThreadSafeStore 本质上是threadSafeMap实现的所有接口,也是对其中数据的封装,防止外部直接使用map |
可以看到这里定义了包括增删改查等所有对数据进行操作的函数,而前面所说的threadSafeMap均实现了这里面所有的接口,因此在实际使用的时候都是通过ThreadSafeStore接口来进行操作,这样做的目的也很容易理解:将数据隐藏,只暴露操作这些数据的接口。实际就是面向对象的理念。
1.1.1.2、如何创建
在创建新的数据时,由于threadSafeMap是这个package里面“不可导出”的,虽然创建的是threadSafeMap实例,但函数真正的返回值是ThreadSafeStore这个接口
1 | func NewThreadSafeStore(indexers Indexers, indices Indices) ThreadSafeStore { |
NewThreadSafeStore的被调方有2个,一个是创建Store的时候,另一个是创建Indexer的时候,后面会讲到。
这里有2个可能需要注意的问题:
threadSafeMap的定义里面items map[string]interface{},但是在创建时items: map[string]interface{}{},后面的{}其实是对这个map的初始化,这时候items已经不为nil了NewThreadSafeStore函数中似乎并没有对lock sync.RWMutex进行显式初始化,go语言中这种初始化方式中某个成员变量没有指定,那么它的值就是该成员变量类型的零值
1.1.2、cache
了解了最底层的数据结构threadSafeMap和其实现的接口ThreadSafeStore之后,接下来看其更上一层的封装cache和其实现的接口Store和Indexer。注意cache既是这个结构体的名字,也是当前这个package的名字,可见其重要性。
从其成员变量中可以看到cache相对于threadSafeMap而言最大的区别是多了一个KeyFunc(其定义是通过obj返回其对应的key字符串,这个key主要是给map做唯一索引用的)。
代码位于staging/src/k8s.io/client-go/tools/cache/store.go
1 | // cache定义了对出对象的key索引函数,并实现了ThreadSafeStore的所有方法 |
1.1.2.1、实现的接口Store
可以看到,实现了Store接口的cache结构体相比于实现了ThreadSafeStore接口的threadSafeMap结构体也只是多了一个keyFunc而已,并且Store中没有用到indexers函数,仅仅只是一个通过key值来做索引的map。常用的keyFunc是MetaNamespaceKeyFunc,即取对象的{namespace}/{name}作为key。
1 | // Store是一个通用的对象存储接口,并没有index的能力,因此常常用来做list-watch的队列载体 |
之所以先定义一套Store接口,是因为有很多地方其实并不需要使用索引功能,而只是需要一个线程安全的map而已(例如队列Queue)。
1.1.2.2、实现的接口Indexer
cache除了实现了Store的接口以外,还实现了Indexers的接口,前者是informer使用的方式,后者是reflector的使用方式,注意这一点十分重要。Indexer本质上就是一个可以定义索引器的Store:
1 | // Indexer是一个带有索引功能的对象存储接口,通常用来作为list-watch的缓存器 |
Indexer可以说是最具有效率的一套存储器接口,原因在于它实现了根据索引来实时分类的功能,什么意思呢?当你定义了这个Indexer的IndexFunc,那么一旦有元素加入到这个Store中来,就会自动给这个元素分组(根据IndexFunc计算的key来进行分组)。这有什么好处呢?假如我需要根据namespace来进行索引(在k8s中这是最常见的索引方式),那么IndexFunc就是根据obj来返回其对应的namespace的值。设想一下如果没有自动索引的功能,我想要查询某个namespace下的所有对象,就需要遍历所有的对象并选出在这个namespace下的对应,需要做一次全量的遍历,而实现了实时索引功能的indexer就不通,由于我已经实现定义了IndexFunc,在每个对象增加进来的时候,我已经根据namespace来分类了(通过threadSafeMap中的indices来维护,indices实际是个map[string][string]sets.String),那么需要查询这个namespace下的所有对象时就只需要直接返回这个set就可以了,不需要遍历所有的对象。当前这个需要在每个对象发生变化的时候事先索引,存在一定的开销,但是对于查询操作带来的便捷是十分巨大的。
以上描述都是通过基本的接口和数据结构来实现的,对应的代码都在staging/src/k8s.io/client-go/tools/cache/index.go中。
首先是检索函数IndexFunc,它定义如下:
1 | // IndexFunc knows how to provide an indexed value for an object. |
需要注意以下几点:
IndexFunc的返回值是一个字符串的slice,而不是一个单独的字符串,这意味着IndexFunc可以是复合类型的索引,这也是为什么Index是一个map。疑问:是否过度设计?Indexer的IndexFunc和cache的keyFunc不同,keyFunc计算的是对象的唯一确定性key(所以返回的是一个字符串而不是字符串slice),不同对象经过keyFunc计算出来的key在这个store中是全局唯一的;而IndexFunc是一类对象的key,可能有多个对象都能通过这个IndexFunc计算出相同的key(譬如不同pod的namespace是一样的),这也是设计IndexFunc的初衷
为了实现这些逻辑,indexer中还设计了几个关键的数据结构(这几个实际上是threadSafeMap中的元素)
1 | // Index的key是IndexFunc计算出来的索引值,value是计算出相同索引值的元素的key |
其中最需要注意的是type Index map[string]sets.String,这里面的sets.String存放的其实就是Store中map的key(也就是keyFunc返回的对象的唯一确定性key)。
1.1.2.3、如何创建
由于cache在这个package中是“不可导出”的,并不被直接引用,而是通过其实现的两个接口Store和Indexer来使用:
1 | // NewStore返回的只是一个多了keyFunc的threadSafeStore,但是Indexers是空的 |
这里需要想办法举一个例子。
1.1.3、总结
本章节介绍了list-watch机制中最基础的数据结构threadSafeMap和cache,其本质是对一个map[string]interface{}进行增删改查,cache比threadSafeMap多了一个可以定义计算唯一索引方法(map的key值)的函数。为了便于对这个map中的对象进行分类,threadSafeMap中使用了indexers和indices这两个元素,用来维护根据不同维度来对所有对象进行分类的map。cache基于threadSafeMap中的函数实现了Store和Indexer两个interface,区别在于前者是不带分类功能(indexers为空),后者带分类功能。从interface上来讲,关系则稍显复杂,可以把Store当做最基本的操作interface,可拓展的方向很多,Indexer则是其中一种拓展,主要是增加了分类的功能,是Informer的基础。后面会讲到的Queue也是Store的一种拓展,增加了队列相关的出队列(Pop)功能。
这其中几点关键信息需要记住:
- 本章最重要的数据结构是
cache这个结构体 cache本质上是一个具有检索和自动分类功能mapcache实现了Store和Indexer两个接口,后者是前者的拓展,比前者多的就是自动分类功能Store是Reflector的基础数据结构Indexer是Informer的基础数据结构
截止到目前,我们看到的主要就是跟
cache相关的数据结构和接口,那么这些跟生产者消费者有什么关系呢?更确切地说,他们跟list-watch是什么关系呢?其实这个cache是list-watch的全量资源缓存,用来将提高查询的效率,降低client和server端的cpu消耗。当然这只是”然”,还需要搞懂”所以然”,我们带着这些疑问继续往下看。
1.2、基础数据结构FIFO和DeltaFIFO
在生产者消费者模型中,最重要的一个数据结构实际上是队列:
- 生产者将消息或者数据放入到队列中
- 消费者从队列中取出消息或者数据并对其进行处理
1.2.1、FIFO
由于go语言的官方库中并没有实现队列这个数据结构,k8s中自己实现了一套。FIFO是一个先入先出的队列,其中存放关键数据的元素是items map[string]interface{}和queue []string,items中存放的是所有的元素,queue中是通过map中的key值来存放的实际队列(通过slice实现,新增的元素append到最后,pop时取第一个),也就是说FIFO是通过map和slice这两个基础类型来配合实现的。
1 | // FIFO 的生产者是Reflector,消费者调用Pop()函数来获取队首的元素 |
如何创建
创建一个新的FIFO只需要传入进行唯一索引值计算的KeyFunc就可以了
1 | // NewFIFO returns a Store which can be used to queue up items to |
实际上在k8s的大部分场景并没有使用到FIFO,仅scheduler中使用到了,而在list-watch中主要使用到了后面讲到的DeltaFIFO。
1.2.2、DeltaFIFO
在FIFO中,队列中的元素(实际是map中的value,而不是slice中的key)是一个无状态的对象interface{},这对于watch事件而言是不够的,watch中需要知道这个对象是新增、删除还是更新,因此k8s又封装了一个叫做DeltaFIFO的队列,主要区别在于结构体中的元素items map[string]interface{}改成了items map[string]Deltas,你可以把他看成是消息或者事件。
1 | // DeltaFIFO的生产者是Reflector,消费者调用Pop()函数来获取队首的元素 |
从结构体中可以看到DeltaFIFO与FIFO的两处区别:
item中的value从interface{}变成了Deltas,Deltas是一个带有事件类型DeltaType的interface{}。
1 | // DeltaType is the type of a change (addition, deletion, etc) |
- 多了一个
knownObjects字段,其类型是KeyListerGetter这个接口,实际创建DeltaFIFO时这里传进来的是一个cache,由于KeyListerGetter只有GetByKey和ListKeys,因此knownObjects只具有读权限
1 | // A KeyListerGetter is anything that knows how to list its keys and look up by key. |
如何创建
创建一个DeltaFIFO除了要传入进行唯一索引值计算的KeyFunc以外,还需要传入实现了KeyListerGetter接口的对象。从前文的解析中可以发现,Store和Indexer中均实现了KeyListerGetter,由此不难想到这里传入的要么就是Store要么就是Indexer了。于是队列(DeltaFIFO)就和缓存(cache)链接了起来,这也是list-watch机制中至关重要的一个联系。
1 | func NewDeltaFIFO(keyFunc KeyFunc, knownObjects KeyListerGetter) *DeltaFIFO { |
1.2.3、实现的接口Queue
好,当前这一小节到目前为止都是在说队列的数据结构,其实外部传递的还是FIFO和DeltaFIFO实现的Queue这个接口:
1 | // Queue是Store的一个拓展,具有队列的Pop功能 |
可以看到,辛辛苦苦讲一节,最终还是回到了原点:Queue其实是增加了队列功能的Store,相比而言只多了4个接口而已。关于Store接口可以看看上一节。另外还有一个关键的信息是,无论是FIFO还是DeltaFIFO,除了队列的操作以外,同cache一样也实现了Store接口。
1.2.4、和cache/FIFO的比较
1.2.4.1、结构体成员的区别
这里先对比一下cache结构体:
- cache中有
indexers和indices来实现同类型资源的分类功能,FIFO/DeltaFIFO中没有,也无需处理 - FIFO/DeltaFIFO中同样需要有map来保存所有的原始数据
- FIFO/DeltaFIFO中多了一个通过slice实现的queue队列,这个队列中只保存需要处理的元素的key值,以减小队列的大小
- FIFO中多了一个条件变量
sync.Cond,用来做消息同步(Pop时如果队列为空则等待有新元素加入的消息) - DeltaFIFO相较于FIFO而言map中的值(
Deltas)不一样,可以处理元素的操作类型,甚至可以处理元素的删除事件,并且当执行Pop出队时返回的是一个slice, - DeltaFIFO相较于FIFO多了一个knownObjects,这个在list-watch的时候十分重要,一旦某个周期中的list-watch失败了,会触发新的list-watch周期,在这个周期的开始阶段,会list一把最新的资源,并更新队列中的所有数据
| cache | FIFO | DeltaFIFO |
|---|---|---|
| lock sync.RWMutex | lock sync.RWMutex | lock sync.RWMutex |
| items map[string]interface{} | items map[string]interface{} | items map[string]Deltas |
| keyFunc KeyFunc | keyFunc KeyFunc | keyFunc KeyFunc |
| indexers Indexers | cond sync.Cond | cond sync.Cond |
| indices Indices | queue []string | queue []string |
| populated bool | populated bool | |
| initialPopulationCount int | initialPopulationCount int | |
| closed bool | closed bool | |
| closedLock sync.Mutex | closedLock sync.Mutex | |
| knownObjects KeyListerGetter |
1.2.4.2、接口实现的区别
我们对比一下目前已经讲过的几个接口:
| 接口 | ThreadSafeStore | Store | Indexer | Queue |
|---|---|---|---|---|
| ThreadSafeStore的接口 | 继承并增加了KeyFunc |
实现了Store |
实现Store |
|
| NA | NA | 增加了索引功能 | 增加了队列功能 | |
| 结构体 | threadSafeMap | cache/FIFO/DeltaFIFO | cache | FIFO/DeltaFIFO |
可以看到,实现了Indexer和Queue接口的对象其实也实现了Store接口,因此FIFO和DeltaFIFO也都实现了Store的接口。但是与cache不同的是,FIFO和DeltaFIFO所实现的Store中的Resync()和Replace()完全不同,可以看到Resync()其实是专门为队列设计的:
| Store接口 | cache |
FIFO |
DeltaFIFO |
|---|---|---|---|
Replace() |
重建items和indices | 更新items和queue | 更新items和queue(该删的删) |
Resync() |
无具体实现 | 同步items与queue | 同步items与queue |
这里其实需要重点讲一下DeltaFIFO的Replace()和Resync(),建议大家去看看实际的代码实现:
Replace(list []interface{}):将新的list全部以”Sync”事件加入到队列中(即使这个元素不在当前队列中),然后将新的list中已经没有的元素增加其”Deleted”事件(这个过程比较有意思,如果DeltaFIFO的knownObjects不为空就遍历knownObjects,否则遍历DeltaFIFO的items,list中没有就”Deleted”)Resync():如果DeltaFIFO的knownObjects为空就直接返回,如果不为空则将knownObjects中的所有元素以”Sync”事件加入到队列中(估计是因为有这个机制,所以Replace中优先使用knownObjects来遍历)
1.2.4.3、功能的区别
通过结构体和接口实现的区别不难窥见:
cache用来存放最新的全量数据(无论是否变化)FIFO/DeltaFIFO用来存放变化(增/删/改/同步)的数据
也就是说,cache中存放的是list出来的所有数据(很多数据可能是一直没有修改),FIFO/DeltaFIFO中存放的是watch到的变化(增删改)并且是需要去做对应处理的数据,这一点对于理解为什么要同时有cache/FIFO/DeltaFIFO这几个结构体、Store/Indexer/Queue这几个接口十分重要,后面讲到的关键数据结构Reflector和Informer也依赖于前面的这些基本的数据结构和接口。这时候你可能已经猜到这几个基本数据结构在整个list-watch中的角色了,我们接着往下看。
1.2.5、总结
这一章节我们讲到的是生产者消费者中最关键的数据结构队列,包含FIFO和DeltaFIFO,其本质都是一个slice,两者在结构上稍微有些差别:
DeltaFIFO比FIFO多了元素的操作类型,因此可以根据元素的增删改作出不同的处理DeltaFIFO会保存同一个元素的所有操作历史(相同操作会去重),FIFO只会保留元素最新的状态DeltaFIFO的Pop函数中传入的PopProcessFunc可以对元素的增删改作出不同的处理,FIFO则只能处理最新的
除了FIFO和DeltaFIFO以外,我们还讲到了这两个对象实现了的接口Queue,本质上Queue是一个实现了队列操作的Store。
了解完队列相关的数据结构,你是不是对后面可能要讲到的内容有一定的预期了呢?
1.1节讲到的cache用来做全量资源的缓存,1.2节讲到的队列用来处理增删改的事件,这些都是list-watch的生产者消费者框架中重要的数据结构,那么一定有其他的数据结构和算法来把他们组织起来,从之前了解到的list-watch的client端画像来看,这个client一定有段逻辑来维护cache这个全量缓存并通过队列来把生产者与消费者组织起来。
我们不妨大胆做一个猜测:可能是先到server端全量list一把,然后存到cache中,剩下的事情就是从server端不断watch新的变化并加入到队列中,这个队列的消费者那里除了将变化更新到cache中之外,还会对这个变化做出相应的处理。
1.3、关键数据结构Informer和Reflector
1.1和1.2章节讲到的都是生产者消费者模型中最基本的数据结构,接下来我们要讨论的是将生产者消费者模型组织起来的关键数据结构informer和reflector,这也是在k8s的client中直接使用的数据结构,其中会使用到我们前面讲到的基础数据结构。
这里有必要提前说明一下informer、reflector、Indexer这几者的区别:参考资料
Reflector:reflector用来watch特定的k8s API资源。具体的实现是通过ListAndWatch的方法,watch可以是k8s内建的资源或者是自定义的资源。当reflector通过watch API接收到有关新资源实例存在的通知时,它使用相应的列表API获取新创建的对象,并将其放入watchHandler函数内的DeltaFIFO队列中。Informer:informer从DeltaFIFO队列中弹出对象。执行此操作的功能是processLoop。base controller的作用是保存对象以供以后检索,并调用我们的控制器将对象传递给它。Indexer:索引器提供对象的索引功能。典型的索引用例是基于对象标签创建索引。 Indexer可以根据多个索引函数维护索引。Indexer使用线程安全的数据存储来存储对象及其键。 在Store中定义了一个名为MetaNamespaceKeyFunc的默认函数,该函数生成对象的键作为该对象的<namespace> / <name>组合。也就是说,reflector是真正的生产者,informer则是消费者,由此可以推测reflector中一定有队列,informer中一定有逻辑来调用这个队列的Pop函数来进行处理。
1.3.1、Reflector
我们先来看Reflector的结构体,之前已经说到Reflector是生产者,那么它的数据结构是什么样的呢?
1 | // Reflector仅监听一种k8s资源的变化并放置到存储器(队列)中 |
以上是Reflector的所有成员变量,从中不难看出这些成员之间的配合关系,在此简单梳理一下Reflector实际的执行逻辑(即Reflector的Run()函数逻辑,代码位于staging/src/k8s.io/client-go/tools/cache/reflector.go):
- 首先list一把当前这个资源类型的所有数据,然后调用
DeltaFIFO的Replace()将list到的新数据同步到队列中,并将当前的版本号记录到lastSyncResourceVersion中 - 起一个协程(收到stop信号或resync报错时退出),以
resyncPeriod为周期,每次都通过ShouldResync函数判断(nil时默认执行)是否需要重新同步,是则将DeltaFIFO中的knownObjects(不为nil的情况下)遍历,并将DeltaFIFO队列中不存在的元素加入到队列中(DeltaType为Sync) - 起一个死循环(收到stop信号时退出),watch对应类型的资源,一旦有新事件产生则调用
DeltaFIFO的增删改接口加入到队列中去
值得注意的是,list只在watch之前执行一次,在watch的过程中并不会重新list,而只是会定期“整理”(
Resync(),与DeltaFIFO中的knownObjects对比)队列中的元素。只有当watch报错时才会重新触发list-watch。
由此可以看出,这个过程中除了watch到了应该关注的增删改事件之外,还产生了很多DeltaType为Sync的事件,为什么需要产生这中类型的事件?这些事件是如何处理的呢?另外Reflector究竟是在被谁使用?我们且带着疑问继续往下看~
Reflector的Run()函数逻辑(可以跳过)
如何创建
1 | // NewNamedReflector same as NewReflector, but with a specified name for logging |
1.3.2、Controller
前面讲到了Reflector是生产者,Informer是消费者,但是中间需要有一个桥梁来将两者关联起来,而这个角色就是Controller来扮演的,它会将生产者和消费者都运行起来。
1 | // Controller is a generic controller framework. |
Controller中的运行逻辑比较简单,这里我们直接用代码说明一下:
1 | // Run中创建一个reflector并起一个协程将其Run起来,然后不停执行processLoop用来Pop队列中的元素并处理 |
可以看到从reflector到controller都是生产者这边对队列的入队处理以及消费者对出队元素的处理,并没有看到全量缓存的踪迹,其实这个是要留给Informer来做的,另外对队列中Pop出来的元素进行处理也是config中的Process函数的事情,这个处理函数也是Informer中定义的。
1.3.3、Informer
我们先看一下Informer的结构体
1 | type sharedIndexInformer struct { |
interface
1 | // SharedInformer has a shared data cache and is capable of distributing notifications for changes |
1 |
|
1.3.4、总结
1.4、各个k8s资源的informer实现
2、关键运行流程
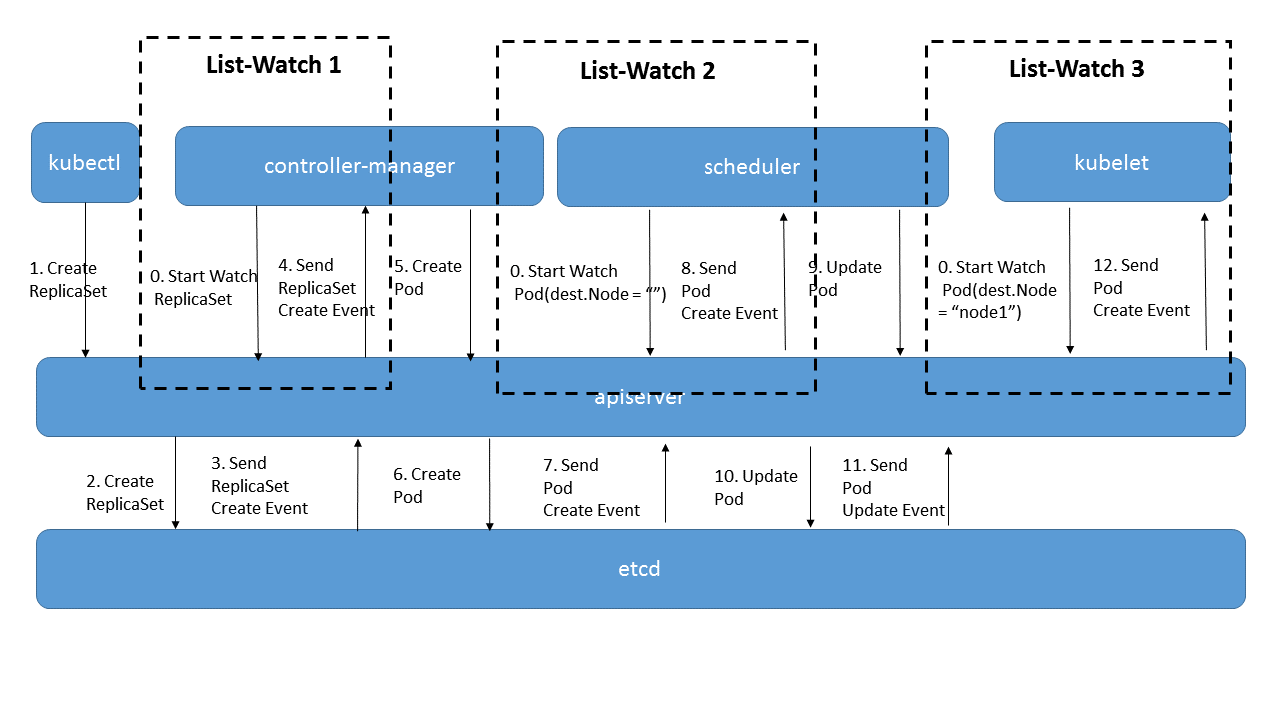
NewSharedInformerFactory
- Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod
- Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中
- 如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
- Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件;如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件
- Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO
- DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1
- DeltaFIFO 再 Pop 这个事件到 Controller 中
- Controller 收到这个事件,会触发 Processor 的回调函数
- LocalStore 会周期性地把所有的 Pod 信息重新放到 DeltaFIFO 中
3、如何写一个自定义的controller
4、List-Watch中的设计理念
4.1、合理利用计算和存储资源,功夫下在每分每秒
threadSafeMap中的indices这个map的维护是深得这一理念的真传:
- 增删改的时候维护好分类好的芸芸众生(功夫下在平时,多消耗一点计算和存储资源)
- 查的时候直接按照分类返回同类(响应时间)
这个跟微信达人们使用微信分组是多么像啊:
- 平时管理好友时做好分组
- 发朋友圈时直接选择可见的分组
4.2、封装,接着封装
几个断言:
1 | func NewThreadSafeStore(indexers Indexers, indices Indices) ThreadSafeStore { |
1 | // 用于确认cache实现了Store的所有接口,否则编译会出错 |
1 | // NewStore returns a Store implemented simply with a map and a lock. |
1 | var ( |
1 | var ( |