/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ funcreverseList(head *ListNode) *ListNode { var pre *ListNode for head != nil { tmp := head.Next head.Next = pre pre = head head = tmp } return pre }
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ funcreverseBetween(head *ListNode, m int, n int) *ListNode { pre, cur, i := &ListNode{Next: head}, head, 1 for ; i < m && cur != nil; i++ { pre = cur cur = cur.Next } // 要反转的部分的尾巴 tail, nHead := cur, pre for ; i <= n && cur != nil; i++ { tmp := cur.Next cur.Next = pre pre = cur cur = tmp } nHead.Next, tail.Next = pre, cur // 对于 m = 1的情况,head已经被翻转,这时应该返回nHead.Next if m == 1 { return nHead.Next } return head }
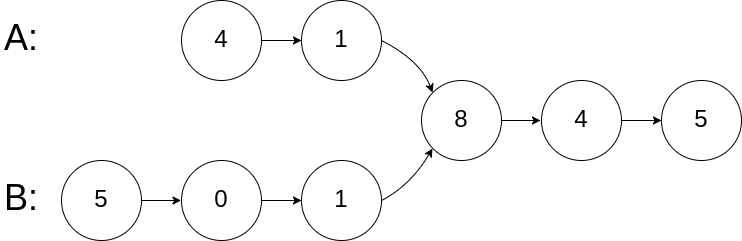
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3 输出:Reference of the node with value = 8 输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
1 2 3
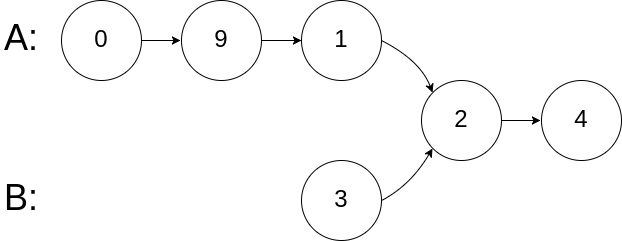
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Reference of the node with value = 2 输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ funcpartition(head *ListNode, x int) *ListNode { left, right := &ListNode{}, &ListNode{} leftHead, rightHead := left, right for ; head != nil; head = head.Next { if head.Val < x { left.Next = head left = head } else { right.Next = head right = head } } left.Next = rightHead.Next right.Next = nil return leftHead.Next }
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ funcmergeKLists(lists []*ListNode) *ListNode { // 一个迭代里面只处理一个最小的node,然后递归 minVal, index := 65535, 0 for i, list := range lists { if list != nil && list.Val < minVal { minVal = list.Val index = i } } if minVal == 65535 && index == 0{ returnnil } head := lists[index] lists[index] = lists[index].Next head.Next = mergeKLists(lists) return head }
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ funcmergeKLists(lists []*ListNode) *ListNode { n := len(lists) if n > 2 { return mergeKLists([]*ListNode{mergeKLists(lists[:n/2]), mergeKLists(lists[n/2:])}) } elseif n == 1 { return lists[0] } elseif n == 2 { if lists[0] == nil { return lists[1] } if lists[1] == nil { return lists[0] } a, b := lists[0], lists[1] if a.Val > b.Val { a, b = lists[1], lists[0] } // 保证cur永远是比b更小的node cur := a for ; cur.Next != nil; cur = cur.Next { if cur.Next.Val > b.Val { cur.Next, b = b, cur.Next } } cur.Next = b return a } returnnil }
funcfindKthLargest(nums []int, k int)int { h := maxHeap{} for _, num := range nums { if h.Len() < k || num >= h.Top() { heap.Push(&h, num) } if h.Len() > k { heap.Pop(&h) } } return heap.Pop(&h).(int) }
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i ,都有一个胃口值 gi ,这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j ,都有一个尺寸 sj 。如果 sj >= gi ,我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
funcjump(nums []int)int { cur, n, step := 0, len(nums), 0 if n < 2 { return0 } for cur + nums[cur] < n-1 { // 贪心,每次跳跃到自己的范围内下次能跳到达的最远的那个点 max, next := cur, cur for i:=cur+1; i <= cur + nums[cur]; i++ { if i + nums[i] > max { max, next = i + nums[i], i } } cur, step = next, step + 1 } return step + 1 }
funcsubsets(nums []int) [][]int { n, result := len(nums), [][]int{} if n == 0 { returnappend(result, []int{}) } for _, v := range subsets(nums[1:]) { result = append(result, v) result = append(result, append([]int{nums[0]}, v...)) } return result }
funcpermute(nums []int) [][]int { iflen(nums) < 2 { return [][]int{nums} } result := [][]int{} for _, v := range permute(nums[1:]) { // 将nums[0]插入到v的任何一个位置生成一个result记录 for i := 0; i <= len(v); i++ { r := append([]int{}, v[:i]...) r = append(r, nums[0]) r = append(r, v[i:]...) result = append(result, r) } } return result }
funcgenerateParenthesis(n int) []string { if n == 0 { return []string{} } result := []string{} generate(n, 0, "", &result) return result } funcgenerate(n, left int, item string, result *[]string) { if left == 0 && len(item) == 2*n { *result = append(*result, item) return } if left < 0 || left > n || len(item) > 2*n { return } if left < n { generate(n, left+1, item+"(", result) } if left > 0 { generate(n, left-1, item+")", result) } }
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ funchasPathSum(root *TreeNode, sum int)bool { if root == nil { returnfalse } // 到达叶子节点 if root.Left == nil && root.Right == nil { return root.Val == sum } return hasPathSum(root.Left, sum-root.Val) || hasPathSum(root.Right, sum-root.Val) }
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ funcpathSum(root *TreeNode, sum int) [][]int { result := [][]int{} if root == nil { return result } sumPath(root, sum, []int{}, &result) return result }
funcsumPath(root *TreeNode, sum int, item []int, result *[][]int) { item = append(item, root.Val) if root.Left == nil && root.Right == nil { if sum == root.Val { *result = append(*result, append([]int{}, item...)) } } if root.Left != nil { sumPath(root.Left, sum - root.Val, item, result) } if root.Right != nil { sumPath(root.Right, sum - root.Val, item, result) } }
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ funcflatten(root *TreeNode) { if root == nil { return } left, right := root.Left, root.Right if left == nil { flatten(root.Right) return } for left.Right != nil { left = left.Right } left.Right, root.Right = right, root.Left root.Left = nil flatten(root.Right) }
funclongestPalindrome(s string)int { hash, n := make([]int, 256), len(s) for i:=0; i<n; i++ { hash[s[i]-'a'] ++ } sum := 0 for _, v := range hash { if v%2 == 0 { sum += v } else { sum += v-1 } } if sum < n { sum ++ } return sum }
funcwordPattern(pattern string, str string)bool { data := strings.Fields(str) iflen(data) != len(pattern) { returnfalse } b2s, s2b := make(map[byte]string), make(map[string]byte) for i, v := range data { if m, ok := b2s[pattern[i]]; ok { if m != v { returnfalse } } else { b2s[pattern[i]] = v } if m, ok := s2b[v]; ok { if m != pattern[i] { returnfalse } } else { s2b[v] = pattern[i] } } returntrue }
funcfindRepeatedDnaSequences(s string) []string { n := len(s) if n <= 10 { return []string{} } hash := make(map[string]int) for i:=0; i<=n-10; i++ { if _, ok := hash[s[i:i+10]]; ok { hash[s[i:i+10]]++ } else { hash[s[i:i+10]] = 1 } } result := []string{} for k, v := range hash { if v > 1 { result = append(result, k) } } return result }
funcnumIslands(grid [][]byte)int { sum := 0 for i, v := range grid { for j, _ := range v { if grid[i][j] == '1' { sum ++ sameIsland(grid, i, j) } } } return sum }
funcsameIsland(grid [][]byte, i, j int) { near := [][]int{{0, 1}, {0, -1}, {1, 0}, {-1, 0}} grid[i][j] = '2' for _, v := range near { if i+v[0] >= len(grid) || i+v[0] < 0 || j+v[1] >= len(grid[0]) || j+v[1]<0 || grid[i+v[0]][j+v[1]] != '1' { continue } sameIsland(grid, i+v[0], j+v[1]) } }
// dfs,会超时 import"math" funcladderLength(beginWord string, endWord string, wordList []string)int { n := len(wordList) for i, v := range wordList { if v == endWord { break } if i == n - 1 { return0 } } num := math.MaxInt64 dfs(beginWord, endWord, 1, &num, wordList) if num == math.MaxInt64 { return0 } return num } funcdfs(beginWord, endWord string, step int, num *int, wordList []string) { if beginWord == endWord { if step < *num { *num = step } return } for i, v := range wordList { if canConvert(beginWord, v) { list := append([]string{}, wordList[:i]...) list = append(list, wordList[i+1:]...) dfs(v, endWord, step+1, num, list) } } } funccanConvert(cur, next string)bool { iflen(cur) != len(next) { returnfalse } sum, n := 0, len(cur) for i:=0; i < n; i++ { if cur[i] != next[i] { sum++ } } if sum == 1 { returntrue } returnfalse }
// 使用动态规划 // d[i]表示以i结束的子数组的最大和,但是这里只依赖d[i-1],因此可以使用一个变量sum来表示 funcmaxSubArray(nums []int)int { max, sum := nums[0], nums[0] for _, v := range nums[1:] { if sum < 0 { sum = v } else { sum += v } if sum > max { max = sum } } return max }
funclengthOfLIS(nums []int)int { // O(nlogn) rec := make([]int, len(nums)) // 记录和更新当前每个位置可能的最小值 res := 0// 当前最长长度,其实也是rec的长度 for i := 0; i < len(nums); i++ { // 二分查找 left, right := 0, res for left < right { mid := (left+right)/2 if rec[mid] < nums[i] { left = mid+1 } else { right = mid } } if right == res { res += 1 rec[right] = nums[i] } else { rec[left] = nums[i] } } return res }
/** Initialize your data structure here. */ funcConstructor()Trie { return Trie{} }
/** Inserts a word into the trie. */ func(this *Trie)Insert(word string) { n := len(word) for i:=0; i<n; i++ { index := word[i] - 'a' // 当前字符不在Trie树中时,增加这个节点 if this.child[index] == nil { this.child[index] = &Trie{} } // this指向下一级,进入下一个循环 this = this.child[index] } // 将最后一个字符标记为End this.end = true }
/** Returns if the word is in the trie. */ func(this *Trie)Search(word string)bool { n := len(word) for i:=0; i<n; i++ { index := word[i] - 'a' // 当前字符不在Trie树中时,返回false if this.child[index] == nil { returnfalse } // this指向下一级,进入下一个循环 this = this.child[index] } // 返回末尾单词的标记 return this.end }
/** Returns if there is any word in the trie that starts with the given prefix. */ func(this *Trie)StartsWith(prefix string)bool { n := len(prefix) for i:=0; i<n; i++ { index := prefix[i] - 'a' // 当前字符不在Trie树中时,返回false if this.child[index] == nil { returnfalse } // this指向下一级,进入下一个循环 this = this.child[index] } returntrue }
/** * Your Trie object will be instantiated and called as such: * obj := Constructor(); * obj.Insert(word); * param_2 := obj.Search(word); * param_3 := obj.StartsWith(prefix); */
/** Initialize your data structure here. */ funcConstructor()WordDictionary { return WordDictionary{ root: &Trie{}, } }
/** Adds a word into the data structure. */ func(this *WordDictionary)AddWord(word string) { root, n := this.root, len(word) for i:=0; i<n; i++ { index := word[i] - 'a' if root.child[index] == nil { root.child[index] = &Trie{} } root = root.child[index] } root.end = true }
/** Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter. */ func(this *WordDictionary)Search(word string)bool { return dfs(this.root, word) }
funcdfs(root *Trie, word string)bool { n := len(word) if n == 0 { return root != nil && root.end } if word[0] == '.' { for i:=0; i<26; i++ { if root.child[i] != nil && dfs(root.child[i], word[1:]) { returntrue } } returnfalse } index := word[0] - 'a' if root.child[index] == nil { returnfalse } if n == 1 { return root.child[index].end } return dfs(root.child[index], word[1:]) }
/** * Your WordDictionary object will be instantiated and called as such: * obj := Constructor(); * obj.AddWord(word); * param_2 := obj.Search(word); */
funcfindCircleNum(M [][]int)int { n := len(M) if n < 2 { return n } head, sum := make([]int, n), n // 初始化head,每个人的head都是自己 for i, _ := range head { head[i] = i } for i:=0; i<n; i++ { for j:=i+1; j<n; j++ { if M[i][j] == 1 { if x, y := find(head, i), find(head, j); x != y { join(head, j, x) sum -- } } } } return sum } // 找到i对应的head funcfind(head []int, i int)int { for head[i] != i { i = head[i] } return i } // 把i这条线路上的所有节点的head都改成j funcjoin(head []int, i, j int) { // 如果i自己不是head,则将i的head也join进来 if head[i] != i { join(head, head[i], j) } head[i] = j }
func(this *NumArray)Update(i int, val int) { i++ diff := val - this.items[i] this.items[i] = val for i<len(this.tree) { this.tree[i] += diff i += i&(-i) } }
func(this *NumArray)SumRange(i int, j int)int { sum, i, j := 0, i+1, j+1 for i--; i > 0; i -= i&(-i) { sum -= this.tree[i] } for ; j > 0; j -= j&(-j) { sum += this.tree[j] } return sum }
/** * Your NumArray object will be instantiated and called as such: * obj := Constructor(nums); * obj.Update(i,val); * param_2 := obj.SumRange(i,j); */