1、整体框架 在了解volcano的结构之前,我们需要先知道为什么要有volcano,它到底解决了哪些kube-scheduler无法解决的问题。要回答这个问题,我们需要先了解kube-scheduler的调度机制,我们知道,kube-scheduler是以pod为单位来进行调度的,除了通过亲和性来做一些pod之间的关系处理之外,并没有任何pod间的关联机制。举一个例子,在AI等训练的场景,是需要一批pod同时工作的,而且这些pod要么一起调度成功,要么一起调度失败,部分调度成功部分调度失败会导致整个任务最重还是失败的,而且调度成功的那些pod还浪费了资源,这种要么一起成功要么一起失败的场景是kube-scheduler无法解决的,所以才催生了volcano以及volcano的前身kube-batch的诞生。
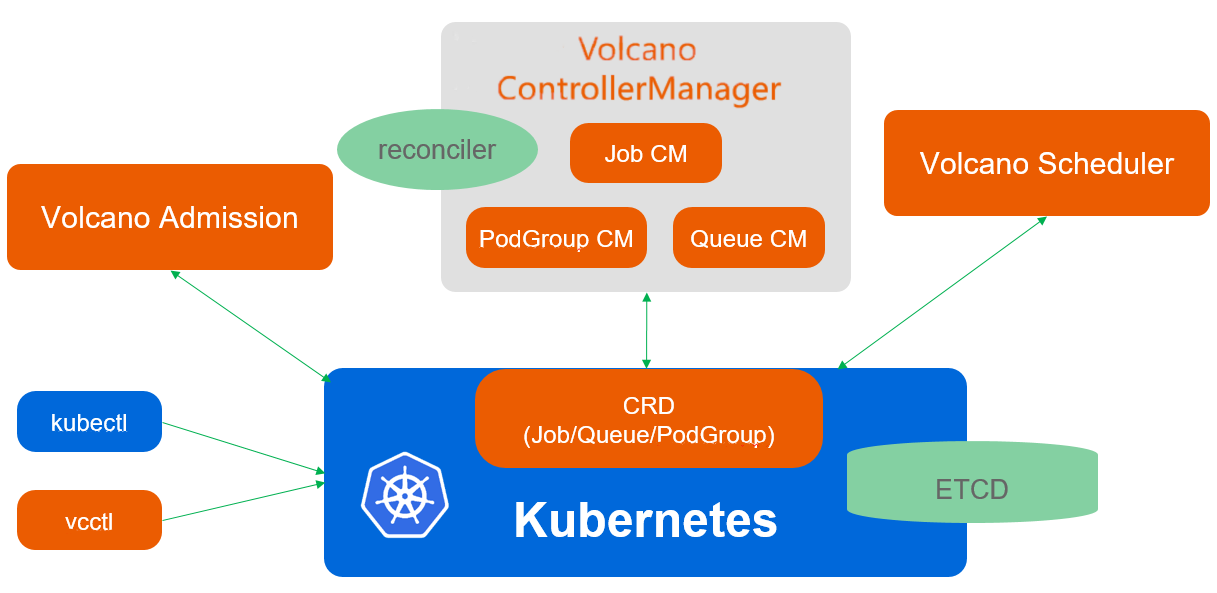
volcano整体架构可以直接参考官方网站的文档 ,这里做一下简要的概述:
volcano主要由scheduler、controller和webhook三部分组成,其中:
scheduler主要负责batch调度,如fair-share(优先调度占用资源少的)、gang-scheduling(pod组批量调度)等
controller主要负责对用户创建的batch.volcano.sh/v1alpha1/job以及其他crd资源进行reconcile
webhook则是对kube-apiserver收到的请求镜像validate和admission处理
2、controller 在了解controller之前,我们需要先了解volcano中到底管理的是哪些CRD资源,在部署volcano的yaml 中可以看到一共创建了4个CRD,分别是Job、Command、PodGroup和Queue。其中每一个controller的功能如下:
2.1、Job 2.1.1、数据结构 2.1.2、代码逻辑 job-controller中主要list-watch的是Job和Pod,同时也会watchCommand资源的add、PodGroup的update和PriorityClasses的add和delete。job controller中有两个特别重要的成员,分别是queueList和cache:
1 2 3 4 5 6 7 8 9 10 type jobcontroller struct { queueList []workqueue.RateLimitingInterface cache jobcache.Cache }
queueList的本质是一个队列,队列的元素是自定义的一个Request对象,可以看到Request中主要包含的是跟Job相关的key信息,这也符合一般的队列模型,queue中存放key,cache中存放实际的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 type Request struct { Namespace string JobName string TaskName string QueueName string Event v1alpha1.Event ExitCode int32 Action v1alpha1.Action JobVersion int32 }
cache的本质是一个Job资源的map,key是namespace/name:
1 2 3 4 5 6 7 8 type jobCache struct { sync.Mutex jobs map [string ]*apis.JobInfo deletedJobs workqueue.RateLimitingInterface }
value中既包含了Job的信息,也包含了这个job对应的Pods的信息
1 2 3 4 5 6 type JobInfo struct { Namespace string Name string Job *batch.Job Pods map [string ]map [string ]*v1.Pod }
知道了controller中的关键的数据结构,我们也就能猜测controller的reconcile的逻辑了:生产者通过list-watch将Job的key信息加入到queueList中,将Job的实体信息保存到jobCache中缓存,消费者从queueList中获取数据并进行处理。其主要代码在processNextReq函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (cc *jobcontroller) processNextReq (count uint32 ) bool jobInfo, err := cc.cache.Get(jobcache.JobKeyByReq(&req)) st := state.NewState(jobInfo) action := applyPolicies(jobInfo.Job, &req) if err := st.Execute(action); err != nil { } queue.Forget(req) return true }
不同Action和State对应的处理逻辑(空白的为KillJob):
Action\State
Pending
Aborting
Aborted
Running
Restarting
Completing
Terminating
Terminated
AbortJob
RestartJob
RestartTask
SyncJob
SyncJob
TerminateJob
CompleteJob
ResumeJob
SyncJob
SyncJob
SyncJob
SyncJob
SyncJob
EnqueueJob
SyncJob
SyncJob
SyncQueue
SyncJob
SyncJob
OpenQueue
SyncJob
SyncJob
CloseQueue
SyncJob
SyncJob
通过以上过程我们可以看到Job的reconcile中存在比较多的状态,因此代码中使用了Action和State两个状态来进行状态机的转移,不过最终处理的逻辑主要就是SyncJob和KillJob两种,因此我们主要分析这两部分的逻辑。
SyncJob从前面状态转移的表格中,我们看到只有Pending和Running状态才有机会进入到SyncJob的流程中,其实也就是从创建Job到Job正常运行的过程,因此可以预料SyncJob主要就是将Job运行起来。主要的流程如下:
对于新Job先进行初始化:创建对应的PVC(volcano中的pvc需要自己管理,没有k8s的controller)和PodGroup(一个Job对应一个PodGroup),注意创建出来的PodGroup则由PodGroup controller管理且其name和Job保持一致
根据Job中的Task变化来生成要创建的pod list和要删除的pod list
分别起协程调用kube-apiserver创建和删除这两个list中的pod,需要注意的是,为了不让k8s的调度器处理这些新创建的pod,Job中需要携带调度器的信息并最终传入到pod上,这样k8s的调度器会过滤掉这些带有volcano调度器名字的pod,同样volcano的调度器则只会过滤出这些带有volcano调度器名字的pod,避免相互影响,在创建Job的时候,webhook中会默认给Job加上volcano这个调度器名字
更新Job的状态,更新jobCache缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 func (cc *jobcontroller) syncJob (jobInfo *apis.JobInfo, updateStatus state.UpdateStatusFn) error if !isInitiated(job) { var err error if job, err = cc.initiateJob(job); err != nil { return err } } else { var err error if err = cc.initOnJobUpdate(job); err != nil { return err } } for _, ts := range job.Spec.Tasks { for i := 0 ; i < int (ts.Replicas); i++ { podName := fmt.Sprintf(jobhelpers.PodNameFmt, job.Name, name, i) if pod, found := pods[podName]; !found { newPod := createJobPod(job, tc, i) if err := cc.pluginOnPodCreate(job, newPod); err != nil { return err } podToCreate = append (podToCreate, newPod) } else { delete (pods, podName) if pod.DeletionTimestamp != nil { klog.Infof("Pod <%s/%s> is terminating" , pod.Namespace, pod.Name) atomic.AddInt32(&terminating, 1 ) continue } classifyAndAddUpPodBaseOnPhase(pod, &pending, &running, &succeeded, &failed, &unknown) } } for _, pod := range pods { podToDelete = append (podToDelete, pod) } } waitCreationGroup := sync.WaitGroup{} waitCreationGroup.Add(len (podToCreate)) for _, pod := range podToCreate { go func (pod *v1.Pod) defer waitCreationGroup.Done() newPod, err := cc.kubeClient.CoreV1().Pods(pod.Namespace).Create(context.TODO(), pod, metav1.CreateOptions{}) }(pod) } waitCreationGroup.Wait() waitDeletionGroup := sync.WaitGroup{} waitDeletionGroup.Add(len (podToDelete)) for _, pod := range podToDelete { go func (pod *v1.Pod) defer waitDeletionGroup.Done() err := cc.deleteJobPod(job.Name, pod) }(pod) } waitDeletionGroup.Wait() newJob, err := cc.vcClient.BatchV1alpha1().Jobs(job.Namespace).UpdateStatus(context.TODO(), job, metav1.UpdateOptions{}) if e := cc.cache.Update(newJob); e != nil { klog.Errorf("SyncJob - Failed to update Job %v/%v in cache: %v" , newJob.Namespace, newJob.Name, e) return e } return nil }
KillJob从前面的表格中可以看出KillJob主要是删除Job或者异常场景触发的,Job并不支持升级操作,只支持扩缩容,因此一旦遇到异常场景会直接触发KillJob,其主要的代码逻辑为:
删除这个job对应的所有的pod,同时统计各个状态的pod的数量
更新Job的状态
删除Job对应的PodGroup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 func (cc *jobcontroller) killJob (jobInfo *apis.JobInfo, podRetainPhase state.PhaseMap, updateStatus state.UpdateStatusFn) error job := jobInfo.Job if job.DeletionTimestamp != nil { return nil } var pending, running, terminating, succeeded, failed, unknown int32 var errs []error var total int for _, pods := range jobInfo.Pods { for _, pod := range pods { total++ if pod.DeletionTimestamp != nil { terminating++ continue } _, retain := podRetainPhase[pod.Status.Phase] if !retain { err := cc.deleteJobPod(job.Name, pod) if err == nil { terminating++ continue } errs = append (errs, err) cc.resyncTask(pod) } classifyAndAddUpPodBaseOnPhase(pod, &pending, &running, &succeeded, &failed, &unknown) } } newJob, err := cc.vcClient.BatchV1alpha1().Jobs(job.Namespace).UpdateStatus(context.TODO(), job, metav1.UpdateOptions{}) if e := cc.cache.Update(newJob); e != nil { klog.Errorf("KillJob - Failed to update Job %v/%v in cache: %v" , newJob.Namespace, newJob.Name, e) return e } if err := cc.vcClient.SchedulingV1beta1().PodGroups(job.Namespace).Delete(context.TODO(), job.Name, metav1.DeleteOptions{}); err != nil { } if err := cc.pluginOnJobDelete(job); err != nil { return err } return nil }
注:job的garbage collector也可以在这里说一下。
总结 通过前面的代码分析可以看到Job Controller主要的逻辑就是根据创建的Job创建对应的PodGroup以及Pod,并且维持Job的各种状态的状态机转移流程。
2.2、PodGroup 2.2.1、数据结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 type PodGroup struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"` Spec PodGroupSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"` Status PodGroupStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"` } type PodGroupSpec struct { MinMember int32 `json:"minMember,omitempty" protobuf:"bytes,1,opt,name=minMember"` Queue string `json:"queue,omitempty" protobuf:"bytes,2,opt,name=queue"` PriorityClassName string `json:"priorityClassName,omitempty" protobuf:"bytes,3,opt,name=priorityClassName"` MinResources *v1.ResourceList `json:"minResources,omitempty" protobuf:"bytes,4,opt,name=minResources"` } type PodGroupStatus struct { Phase PodGroupPhase `json:"phase,omitempty" protobuf:"bytes,1,opt,name=phase"` Conditions []PodGroupCondition `json:"conditions,omitempty" protobuf:"bytes,2,opt,name=conditions"` Running int32 `json:"running,omitempty" protobuf:"bytes,3,opt,name=running"` Succeeded int32 `json:"succeeded,omitempty" protobuf:"bytes,4,opt,name=succeeded"` Failed int32 `json:"failed,omitempty" protobuf:"bytes,5,opt,name=failed"` }
2.2.2、代码逻辑 在Job的控制器中我们看到PodGroup是由Job创建的,并且name还和Job一毛一样,然后在KillJob的时候就会把它直接删了,似乎并没有看到这个PodGroup的功能。实际上这是因为PodGroup的功能相对而言比较简单,主要就是给不是通过Job创建的 pod创建对应的PodGroup。在PodGroup的controller中,分别list了Pod和PodGroup资源,但是只watch了pod的add事件,并且只过滤了没有对应PodGroup的pod,也就是说只有单独创建pod的时候才会加入到消费者队列中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pg.podInformer.Informer().AddEventHandler( cache.FilteringResourceEventHandler{ FilterFunc: func (obj interface {}) bool switch v := obj.(type ) { case *v1.Pod: if v.Spec.SchedulerName == opt.SchedulerName && (v.Annotations == nil || v.Annotations[scheduling.KubeGroupNameAnnotationKey] == "" ) { return true } return false default : return false } }, Handler: cache.ResourceEventHandlerFuncs{ AddFunc: pg.addPod, }, })
在消费者队列中,controller的处理逻辑非常简单,仅对add的新pod进行处理,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func (pg *pgcontroller) processNextReq () bool obj, shutdown := pg.queue.Get() if shutdown { klog.Errorf("Fail to pop item from queue" ) return false } req := obj.(podRequest) defer pg.queue.Done(req) pod, err := pg.podLister.Pods(req.podNamespace).Get(req.podName) if err != nil { klog.Errorf("Failed to get pod by <%v> from cache: %v" , req, err) return true } if err := pg.createNormalPodPGIfNotExist(pod); err != nil { klog.Errorf("Failed to handle Pod <%s/%s>: %v" , pod.Namespace, pod.Name, err) pg.queue.AddRateLimited(req) return true } pg.queue.Forget(req) return true }
有一点需要注意的是,在创建PodGroup的时候,如果pod中已经有QueueName的annotation了,则将QueueName写到PodGroup的Spec中,如果没有则空着。不过admission-controller会给空的Job中加上默认的QueueName,因此通过Job创建的PodGroup会打上默认的QueueName,但是通过Pod创建出来的似乎并没有。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func (pg *pgcontroller) createNormalPodPGIfNotExist (pod *v1.Pod) error pgName := helpers.GeneratePodgroupName(pod) if _, err := pg.pgLister.PodGroups(pod.Namespace).Get(pgName); err != nil { obj := &scheduling.PodGroup{ ObjectMeta: metav1.ObjectMeta{ Namespace: pod.Namespace, Name: pgName, OwnerReferences: newPGOwnerReferences(pod), }, Spec: scheduling.PodGroupSpec{ MinMember: 1 , PriorityClassName: pod.Spec.PriorityClassName, }, } if queueName, ok := pod.Annotations[scheduling.QueueNameAnnotationKey]; ok { obj.Spec.Queue = queueName } if _, err := pg.vcClient.SchedulingV1beta1().PodGroups(pod.Namespace).Create(context.TODO(), obj, metav1.CreateOptions{}); err != nil { klog.Errorf("Failed to create normal PodGroup for Pod <%s/%s>: %v" , pod.Namespace, pod.Name, err) return err } } return pg.updatePodAnnotations(pod, pgName) }
2.3、Queue 2.3.1、数据结构 在volcano中,Queue是一个nonNamespaced资源,它是一个PodGroup的队列
2.3.2、代码逻辑 queue-controller中主要list-watch的是Queue和PodGroup资源,其中有两个成员比较关键,一个是用来保存事件队列的queue,另一个是用来标识所有PodGroup的podGroups。
1 2 3 4 5 6 7 8 9 10 type queuecontroller struct { queue workqueue.RateLimitingInterface podGroups map [string ]map [string ]struct {} }
当watch到新的Queue或者PodGroup资源时,都是将事件组装成带有QueueName的Request加入队列中,需要注意的是,无论是job-controller中还是podgroup-controller中创建的PodGroup都是带有podgroup.Spec.Queue的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func (c *queuecontroller) addQueue (obj interface {}) queue := obj.(*schedulingv1beta1.Queue) req := &apis.Request{ QueueName: queue.Name, Event: busv1alpha1.OutOfSyncEvent, Action: busv1alpha1.SyncQueueAction, } c.enqueue(req) } func (c *queuecontroller) addPodGroup (obj interface {}) pg := obj.(*schedulingv1beta1.PodGroup) key, _ := cache.MetaNamespaceKeyFunc(obj) c.pgMutex.Lock() defer c.pgMutex.Unlock() if c.podGroups[pg.Spec.Queue] == nil { c.podGroups[pg.Spec.Queue] = make (map [string ]struct {}) } c.podGroups[pg.Spec.Queue][key] = struct {}{} req := &apis.Request{ QueueName: pg.Spec.Queue, Event: busv1alpha1.OutOfSyncEvent, Action: busv1alpha1.SyncQueueAction, } c.enqueue(req) }
在消费者端,queue-controller中的逻辑跟job-controller有点类似,先根据Queue的状态生成处理函数,然后根据req中的Action来进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (c *queuecontroller) handleQueue (req *apis.Request) error startTime := time.Now() defer func () klog.V(4 ).Infof("Finished syncing queue %s (%v)." , req.QueueName, time.Since(startTime)) }() queue, err := c.queueLister.Get(req.QueueName) queueState := queuestate.NewState(queue) if err := queueState.Execute(req.Action); err != nil { return fmt.Errorf("sync queue %s failed for %v, event is %v, action is %s" , req.QueueName, err, req.Event, req.Action) } return nil }
类似的,queue-controller也有自己的处理函数转移表
Action\State
Open
Closed
Closing
Unknown
OpenQueue
SyncQueue
OpenQueue
OpenQueue
OpenQueue
CloseQueue
CloseQueue
SyncQueue
SyncQueue
CloseQueue
SyncQueue
SyncQueue
SyncQueue
SyncQueue
SyncQueue
可以看到主要的处理仅包含OpenQueue、SyncQueue和CloseQueue三种,这三种的处理逻辑比较简单,这里就不贴代码直接描述一遍:
OpenQueue:进入到OpenQueue的Queue状态是Closed、Closing和Unknown中的一种,因此OpenQueue做的仅仅是把Queue的状态更新成OpenSyncQueue:主要对该Queue中所有的PodGroup状态进行统计并更新到queueStatus中CloseQueue:跟OpenQueue类似,把Queue的状态更新成Closed
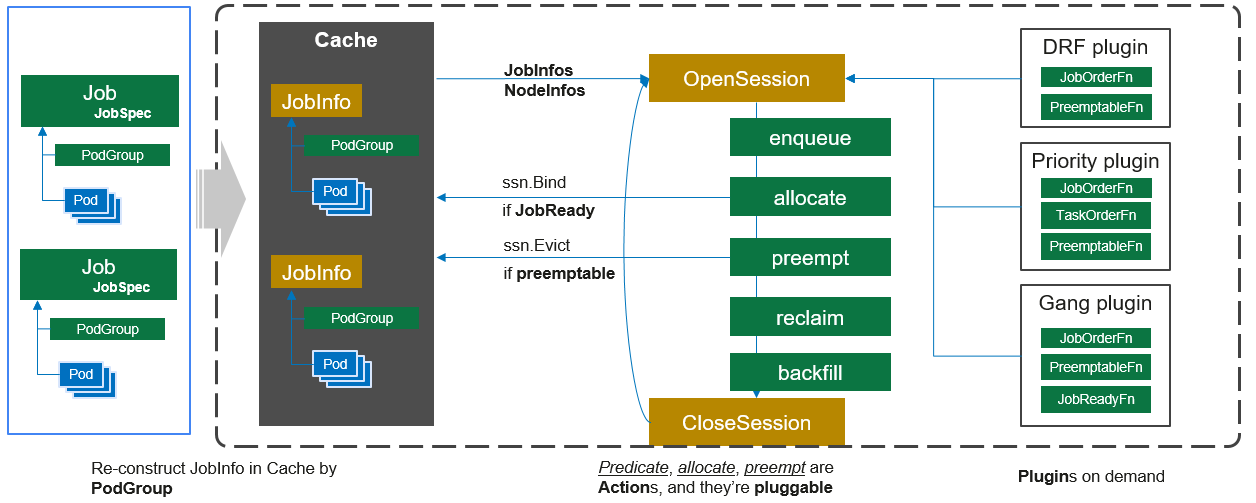
3、scheduler scheduler是volcano的核心,它是以PodGroup为基本单位来进行调度的。
在设计之初我们就把 job和podgroup两个概念分开。所有跟作业相关的信息,都是放在 job里面;所有跟调度相关的信息都放在podgroup里面,这个设计与Kubernetes非常相像。
scheduler的架构可以参考下图:
调度器的本质还是给所有没有绑定到节点上的pod找到合适的节点并绑定上去,但是为了实现gang调度、抢占、资源预留等功能,不能跟k8s的调度器一样通过watch到的pod事件来触发调度(大多数情况下,每一个pod的调度都是单pod最优),所以volcano的调度器采用的是周期性全局调度的方式。我们在看volcano的调度器代码时也能够看到调度逻辑也是这样的思路:
list-watch的是PodGroup和Node
周期性创建一个全局调度的Session,对集群做一次快照
在每一个Session中,根据配置的调度算法和策略对快照中的所有PodGroup进行调度
1 2 3 4 5 6 7 8 9 10 type Scheduler struct { cache schedcache.Cache actions []framework.Action plugins []conf.Tier configurations []conf.Configuration schedulerConf string schedulePeriod time.Duration }
一个默认的配置文件如下:
1 2 3 4 5 6 7 8 9 10 actions: "enqueue, allocate, backfill" tiers: - plugins: - name: priority - name: gang - plugins: - name: drf - name: predicates - name: proportion - name: nodeorder
可以看到其中Action的顺序是enqueue、allocate和backfill,调度器分成两层,一层是priority和gang调度,另一层是drf、predicates、proportion和nodeorder调度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (pc *Scheduler) Run (stopCh <-chan struct {}) go pc.cache.Run(stopCh) pc.cache.WaitForCacheSync(stopCh) go wait.Until(pc.runOnce, pc.schedulePeriod, stopCh) } func (pc *Scheduler) runOnce () pc.loadSchedulerConf() ssn := framework.OpenSession(pc.cache, pc.plugins, pc.configurations) defer framework.CloseSession(ssn) for _, action := range pc.actions { actionStartTime := time.Now() action.Execute(ssn) metrics.UpdateActionDuration(action.Name(), metrics.Duration(actionStartTime)) } }
各个调度器所注册的调度算法如下表所示,“*”表示该调度器注册了该算法。如果要新增一个调度器,那么就只需要去实现对应过程的function并注册进去就可以了。
function\plugin
binpack
conformance
drf
gang
nodeorder
predicate
priority
proportion
jobOrderFn
*
*
*
queueOrderFn
*
taskOrderFn
*
namespaceOrderFn
*
predicateFn
*
nodeOrderFn
*
*
batchNodeOrderFn
*
preemptableFn
*
*
*
*
reclaimableFn
*
*
*
overusedFn
*
jobReadyFn
*
jobPipelinedFn
*
jobValidFn
*
jobEnqueueableFn
*
在volcano的调度器中,当前实现的Action有五个:
enqueue(入队):入队主要就是过滤出需要处理的Job,先通过QueueOrderFn根据优先级将所有要处理的Queue加入到一个队列中,同时每一个Queue上的Job也通过JobOrderFn根据优先级将所有要处理的Job加入到这个Queue的队列中,然后根据Queue和Job的优先级来对每一个Job进行jobEnqueueableFn预判断(当前资源是否满足Job的需求)
allocate(分配):分配其实就是给每一个Task绑定节点,是调度的核心,其处理逻辑主要分以下6步,主要逻辑就是每次选择一个优先级最高的Task,并找到打分最高的节点bind过去,直到所有的Task都处理完
通过NamespaceOrderFn根据优先级选择一个需要去处理的namespace
通过QueueOrderFn根据优先级选择一个需要去处理的Queue
通过JobOrderFn根据优先级选择一个需要去处理的Job
通过TaskOrderFn根据优先级选择一个需要去处理的Task
通过predicateFn过滤去除不满足要求的节点
通过NodeOrderFn来给节点进行打分,并将分数最高的节点bind给这个Task
backfill(回填):volcano中为了避免饥饿而有条件地为大作业保留了一些资源,回填是对剩下来未调度小Task进行bind的过程,对于每一个未调度的Task:
遍历所有节点,通过predicateFn滤除不满足要求的node
尝试将该Task调度到满足要求的节点上
preempt (抢占):抢占是一种特殊的Action,它主要处理的场景是当一个高优先级的Task进入调度器但是当前环境中的资源已经无法满足这个Task的时候,需要能将已经调度的任务中驱逐一部分优先级低的Task,以便这个高优先级的Task能够正常运行,因此其处理过程包含选择优先级低的Task并驱逐的逻辑。其处理流程为,对于PodGroup状态不为Pending的Job
通过jobValidFn和jobPipelinedFn进行过滤
通过JobOrderFn和TaskOrderFn对集群中的Job和Task进行优先级队列的初始化
对于每一个需要进行抢占调度的Task:
通过predicateFn对所有节点进行过滤,通过batchNodeOrderFn、nodeOrderFn、nodeReduceFn对所有节点进行打分和排序
按照分数排序对每个节点上的Task调用preemptableFns判断该Task是否可以抢占(也就是这个Task是否可以驱逐用来腾出资源给待调度的Task),指导找到节点并且可以驱逐的Task腾出来的资源满足待调度的Task为止
对于抢占而言,该Action中同时考虑了跨Queue和Queue内部跨Job之间的抢占
reclaim (回收):在volcano中,集群的资源是根据权重给每一个Queue分配的,当有一个新的Queue创建出来时,第一个Job的Task进行资源调度的时候就会触发回收,也就是对之前创建的Queue中的Task进行驱逐,腾出对应比例的资源给这个新Queue。其处理流程为:
通过queueOrderFn对当前集群中的Queue进行优先级排序
通过JobOrderFn和TaskOrderFn对集群中的Job和Task进行优先级队列的初始化
通过overusedFn过滤掉超配额的Queue
对于每一个Task,通过reclaimableFn来判断是否需要触发回收
对于每一个需要触发回收的Task,执行驱逐操作(其实就是把要驱逐的Pod删掉)
通过以上的归纳其实也可以得到function和action之间的关系(表格中的数字表示调用顺序):
function\action
enqueue
allocate
backfill
preempt
reclaim
jobOrderFn
2
3
3
2
queueOrderFn
1
2
1
taskOrderFn
4
4
3
namespaceOrderFn
1
predicateFn
5
1
5
nodeOrderFn
6
7
batchNodeOrderFn
6
preemptableFn
8
reclaimableFn
5
overusedFn
4
jobReadyFn
jobPipelinedFn
2
jobValidFn
1
jobEnqueueableFn
3
参考文章